
隨著生成式 AI 與大型模型訓練需求快速成長,企業在導入 AI 的過程中通常會面臨以下三項核心問題:
- GPU 資源使用率偏低,造成硬體投資浪費
- 多節點與多雲環境難以統一管理
- 模型開發、訓練與部署流程缺乏整合平台支援
因此,即使具備算力設備,也難以有效支撐大規模 AI 應用發展。
數位無限(INFINITIX)推出的 AI-Stack 平台,正是為解決這類問題而設計的企業級 AI 基礎設施管理解決方案。透過整合 GPU 資源調度、多雲管理能力與 MLOps 流程,AI-Stack 協助企業建立可擴展、可治理且高效率的 AI 運算環境,使 AI 不再只是實驗工具,而成為可穩定支撐營運的核心基礎架構。
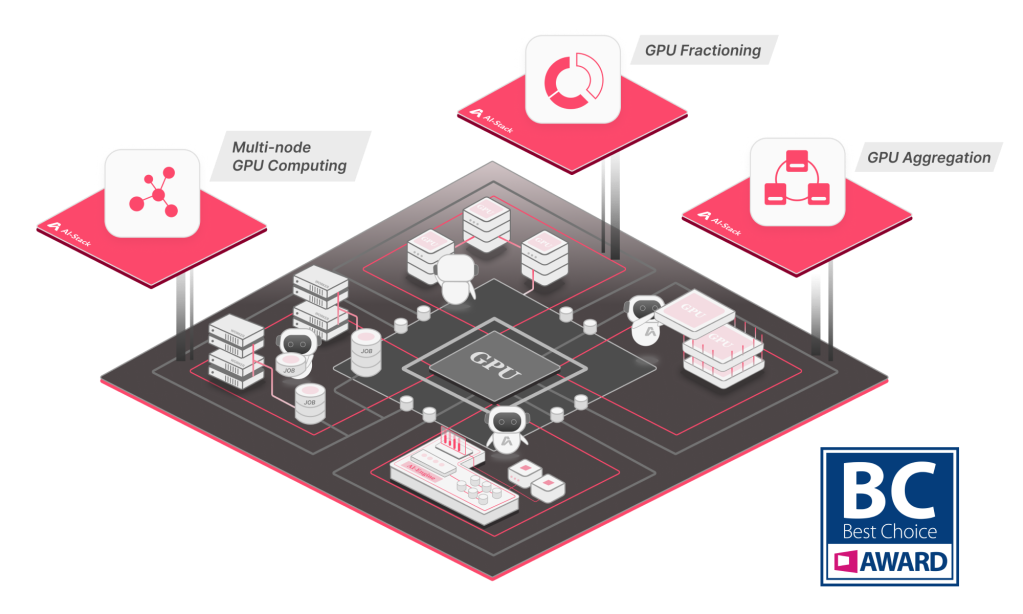
AI-Stack 導入三策略建立企業級 AI 算力治理平台
AI-Stack 透過 GPU 調度能力、多雲整合架構與完整模型生命週期支援,使企業可建立統一且可擴展的 AI 基礎設施管理環境。
策略一:GPU 切割與跨節點運算提升算力使用效率
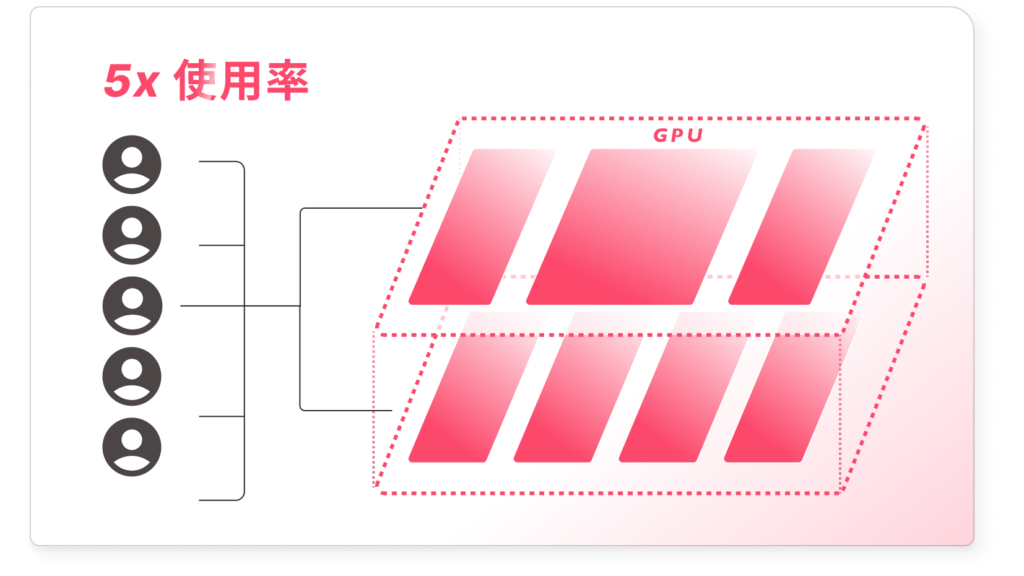
AI-Stack 提供 GPU 切割與聚合能力,使單一 GPU 可分配給多位使用者與多項任務同時運行,有效降低資源閒置情形。
平台支援:
- GPU 切割技術提升多任務並行能力
- Horovod 分散式訓練框架
- DeepSpeed 分散式訓練技術
- HPC 跨節點運算能力
透過這些機制,企業可將 GPU 使用率由傳統約 30% 提升至最高 90%,顯著提升算力利用效率 📈
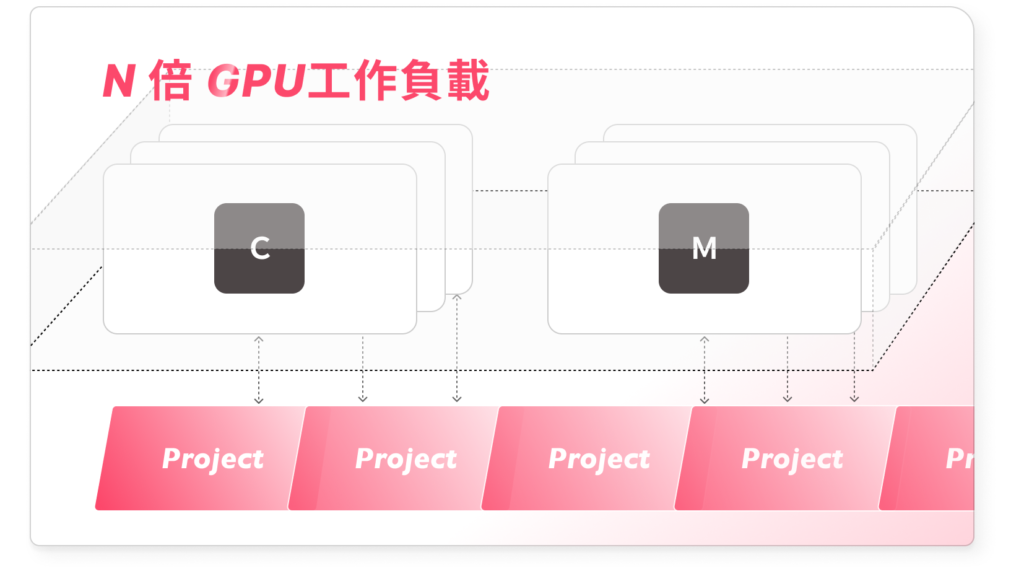
策略二:多雲整合架構統一管理企業 AI 運算環境
AI-在混合雲與跨資料中心部署情境中,統一管理不同品牌 GPU 與運算環境是企業導入 AI 的重要條件。
AI-Stack 支援:
- 公有雲、私有雲與混合雲整合管理
- 多品牌 GPU(如 NVIDIA、AMD)納管能力
- Kubernetes 架構快速部署運算環境
- 多任務並行調度能力
使企業可透過單一平台管理跨環境算力資源,建立完整 AI 基礎設施管理架構。
策略三:整合 MLOps 流程支援模型全生命週期管理
AI-Stack 同時提供模型開發、訓練與推論部署所需的完整工具環境,使企業能建立標準化 AI 開發流程。
平台支援:
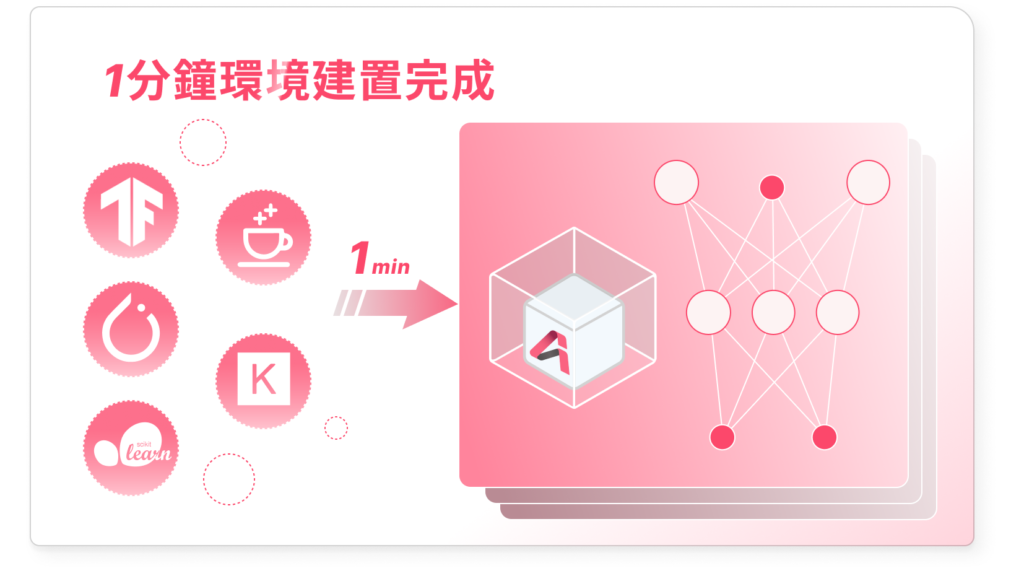
- 模型開發環境一鍵部署(約 1 分鐘完成)
- 單次或批次任務自動執行
- 推論部署服務整合
- MLOps 流程管理能力
透過完整生命週期支援架構,使 AI 模型可快速從開發階段進入正式營運場景。

應用成效:跨產業導入 AI 算力治理平台提升資源利用與營運效率
GAI-Stack 已成功應用於資料中心、金融、醫療、製造與學術研究等多元場域,協助企業優化 GPU 資源配置並提升 AI 應用效率。
例如,在金融產業中,永豐金控運用 AI-Stack 建立內部模型開發與自動化部署平台,支援貸款審核與風險評估分析;在醫療場域中,花蓮慈濟醫院透過平台管理 DGX-A100 系統資源並提升醫療影像診斷效率。
製造產業方面,中鋼集團與中冠資訊合作導入 AI-Stack 進行產線優化與設備良率分析;學術研究場域則由臺北科技大學運用平台支援 AI 課程與研究資源調度,使 GPU 使用更加公平且有效率。
透過智慧調度與資源最佳化機制,企業 GPU 投資效益最高可提升 10 倍,並建立可長期擴展的 AI 算力管理架構

HPE 提供企業級 AI 運算基礎架構支援 GPU 資源調度與模型訓練環境
在企業推動 AI 基礎設施管理平台時,穩定且高效能的運算設備是支撐 GPU 調度與分散式訓練的重要基礎。
AI-Stack 可搭配 HPE 企業級伺服器平台部署,透過整合 GPU 加速資源與高效能運算架構,使模型訓練與推論流程能在穩定環境中執行,並支援跨節點運算與多任務調度需求。
此類架構特別適用於資料中心、金融、醫療與製造等需要高密度算力與長時間穩定運行的場域,協助企業建立可持續擴展的 AI 基礎設施管理平台。






